Understanding the meaning of natural language require a huge amount of information to be arranged by a neural network. And the largest part if this information is usually stored in word embeddings.
Typically, labeled data from a particular task is not enough to train so many parameters. Thus, word embeddings are trained separately on a large general-purpose corpora.
But there are some cases when we want to be able to train word embeddings in our custom task, for example:
- We have a specific domain with a non-standard terminology or sentence structure
- We want to use additional markup like
<tags>in our task
In these cases, we need to update a small number of weights, responsible for new words and meanings. At the same time, we can’t update pre-trained embeddings cause it will lead to very quick overfitting.
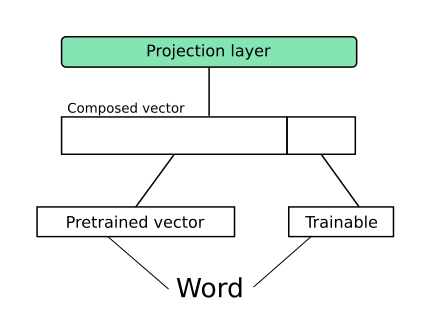
To deal with this problem partially trainable embeddings were used in this project. The idea is to concatenate fixed pre-trained embeddings with additional small trainable embeddings. It is also useful to add a linear layer right after concatenation so embeddings could interact during training. Changing the size of an additional embedding gives control over the number of parameters and, as a result, allows to prevent overfitting.
Another good thing is that AllenNLP allows implementing this technique without a single line of code but with just a simple configuration:
{
"token_embedders": {
"tokens-ngram": {
"type": "fasttext-embedder",
"model_path": "./data/fasttext_embedding.model",
"trainable": false
},
"tokens": {
"type": "embedding",
"embedding_dim": 20,
"trainable": true
}
}
}