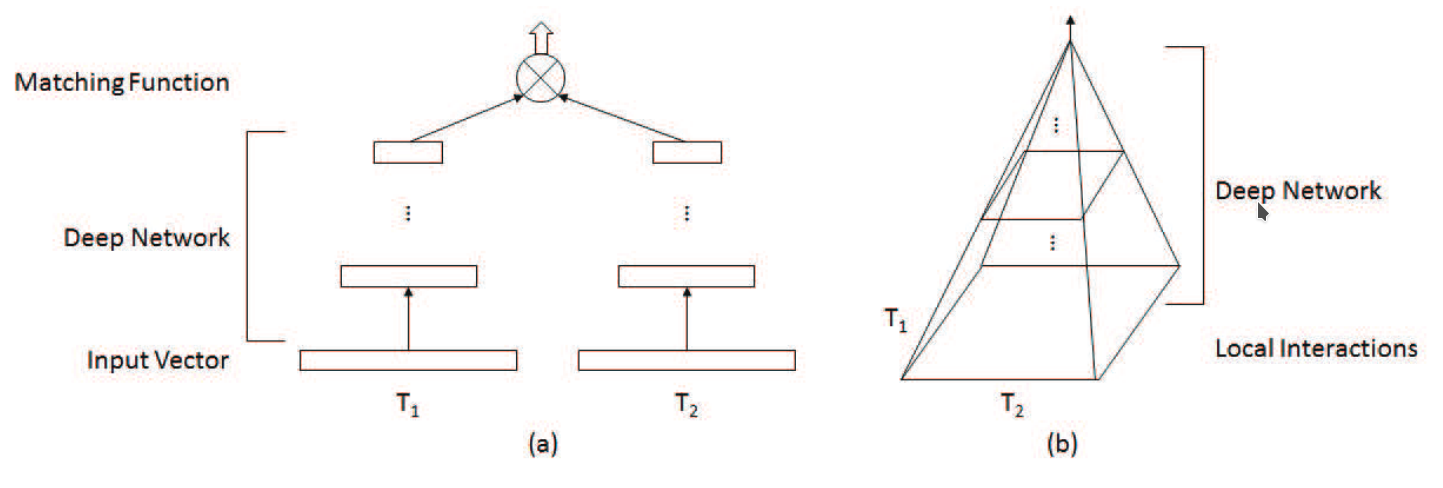
A variety of deep matching models can be categorized into two types according to their architecture. One is the representation-focused model (pic. 1), which tries to build a good representation for a single text with a deep neural network, and then conducts matching between compressed text representations. Examples include DSSM, C-DSSM and ARC-I.
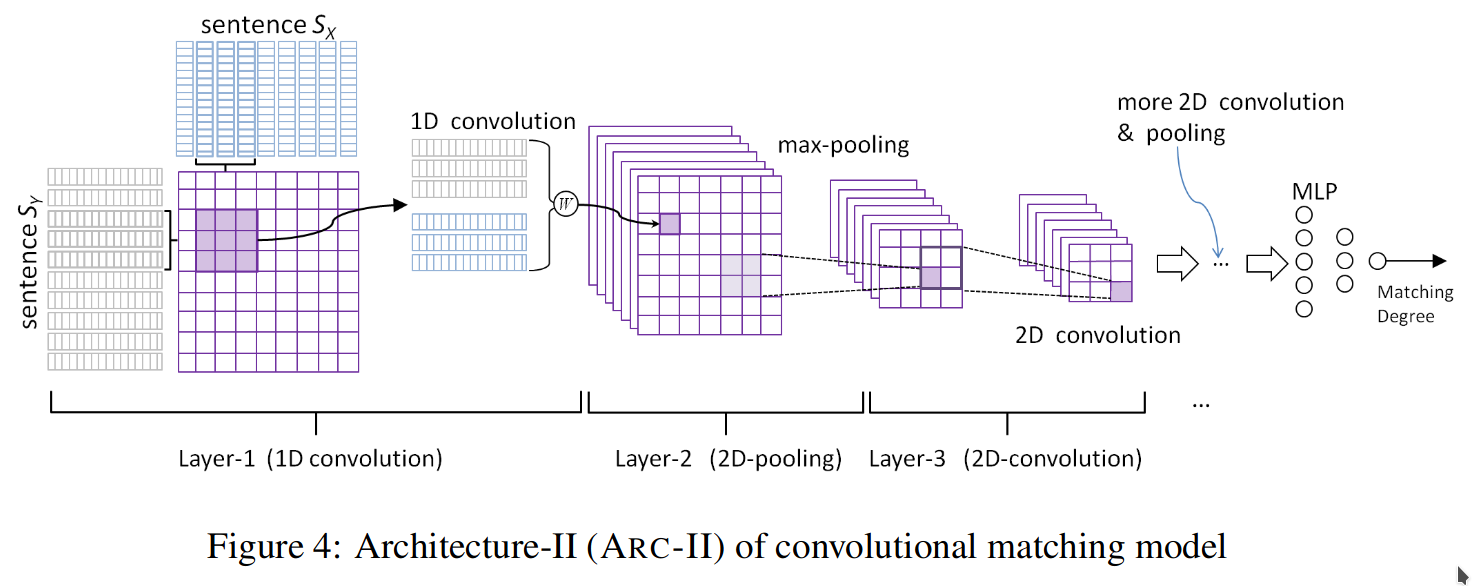
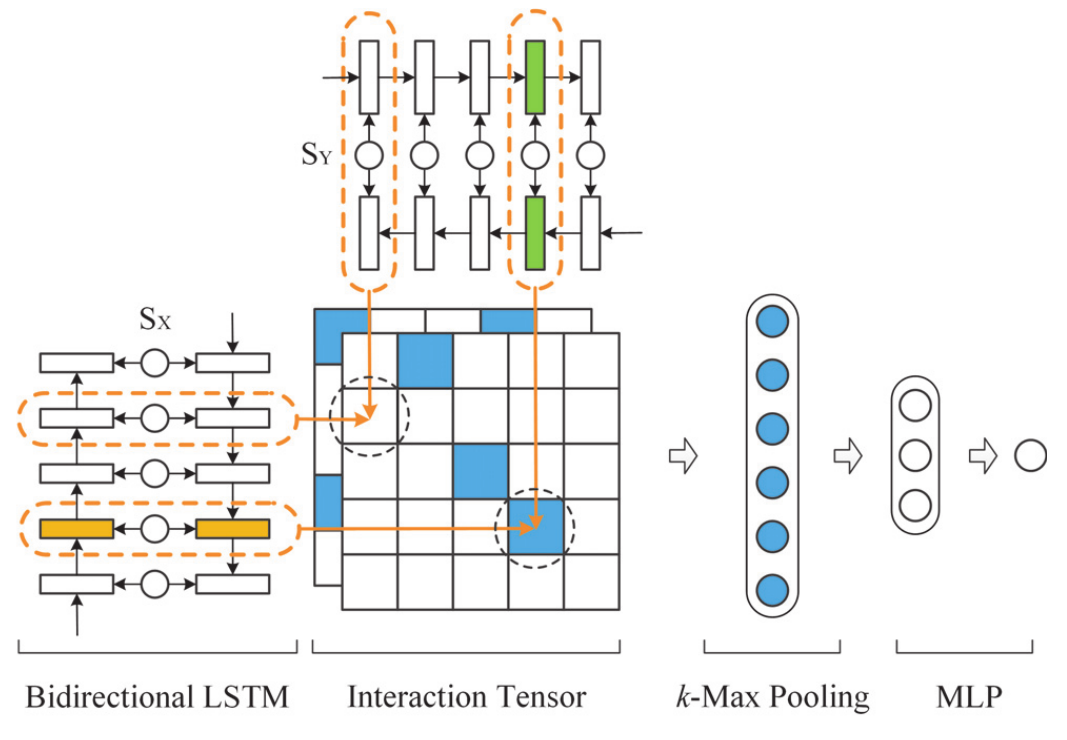
The other is the interaction-focused model (pic. 2), which first builds local interactions (i.e., local matching signals) between two pieces of text, and then uses deep neural networks to learn hierarchical interaction patterns for matching. Examples include MV-LSTM, ARC-II and MatchPyramid.
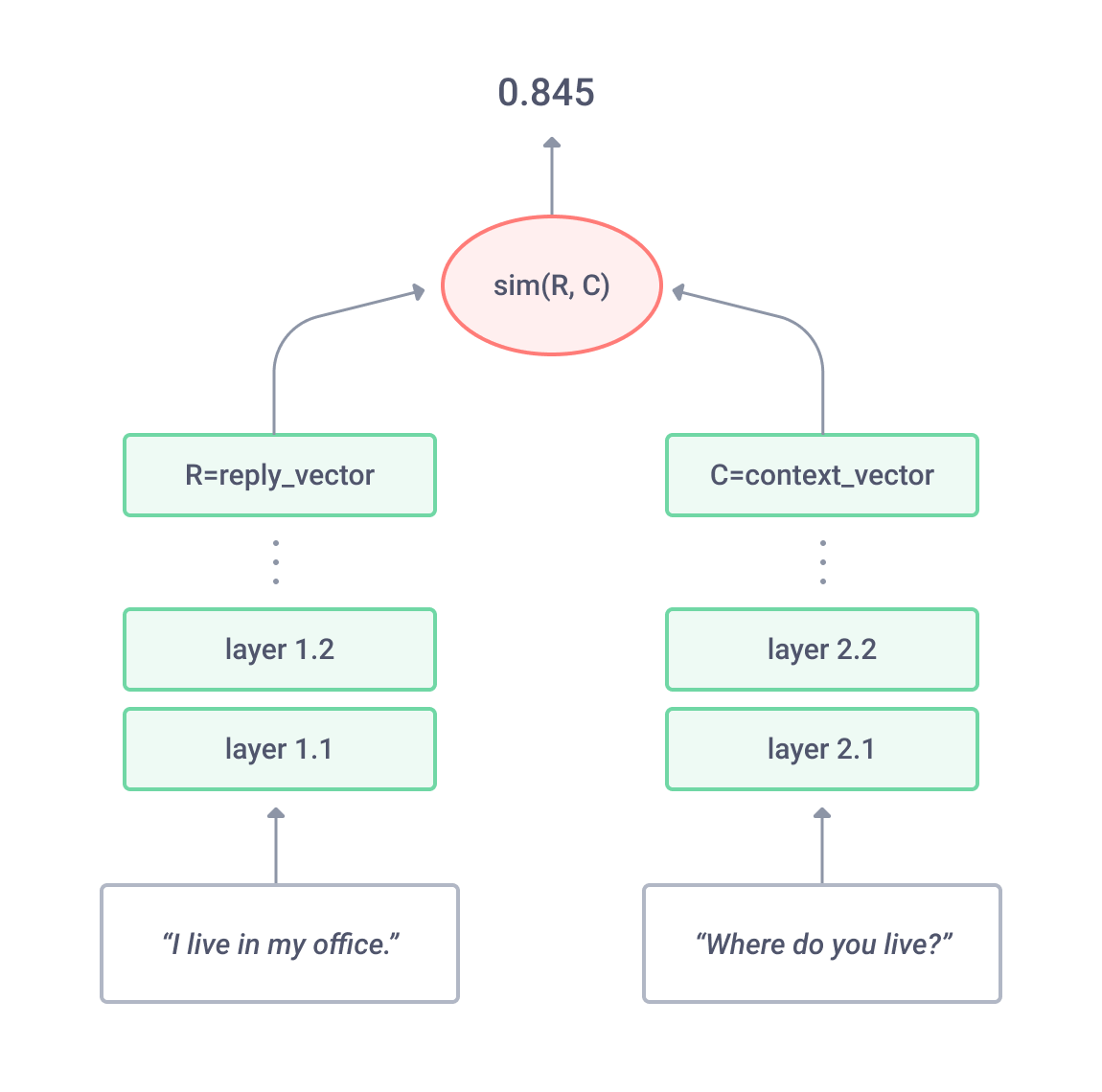
Useful property of representation-focused models is the possibility to pre-compute representation vectors. It allows, for example, to perform fast ranking of web pages in search engines.
However, it does not take into account the interaction between two texts until an individual presentation of each text is generated. Therefore there is a risk of losing details (e.g., a city name) important for the matching task in representing the texts. In other words, in the forward phase (prediction), the representation of each text is formed without knowledge of each other. As a result, interaction-focused models tends to perform better in Question Answering and Paraphrase Identification tasks, though they are not applicable for web-scale matching.