When training neural networks it can often be unclear why the network is not learning. Is it about learning parameters or NN architecture? Brute force search on full training dataset may be very time consuming even with GPU acceleration. If you need to write code on your laptop and run it on remote machine, it makes process even more painful. One way to solve this problem is to use synthetic datasets for debugging.
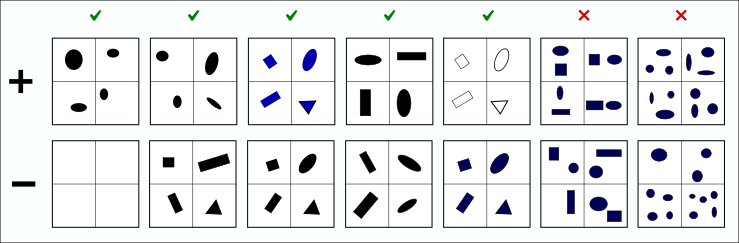
The idea is to create small sets of examples each of which is a little more complex then previous one. Let me illustrate this approach. On picture example we can see that model is able to distinguish:
- Object presence
- Shapes
- Colors
- Rotation
- Stroke
And it can’t distinguish alignment and count of objects. Keep in mind that number of layers and neurons should be scaled down according to the size of synthetic data, or network will overfit. Knowing evaluation results we can quickly iterate over modifications for our network architecture.
Of course solving synthetic dataset does not guarantee solving real-life tasks. As well as passing Unit test does not guarantee that code has no bugs. But there is another useful thing we can do: with large amount of small experiments we can detect relations between the result and changing of network parameters. This information will help us to concentrate on significant parameters tuning while training on real data.
Not only images can synthesized for training. In my NEL project I am using 13 synthetic text datasets. Size of this datasets allows me to debug neural network on laptop without any GPU. You can find code its generation here. Writing code for data generation may be time consuming and boring, so the next possible step in NN debugging is to create tools, framework or even language for data generation. With declarative SQL-like language it would be possible to create datasets automatically, for example using some kind of evolution strategy. Unfortunately I was unable to find anything suitable for this task, so it is a good place for you to contribute!
Practical example.
Situation: CDSSM model does not learn well on big dataset of natural language sentences. What is our next step?
Running the model on several synthetic datasets, we notice that CDSSM model is unable to handle the following simple data:
Each sentence has several of N topic words + random noise words. Two sentences matching only if they have at least one common word.
Example:
1 ldwjum mugqw sohyp sohyp dwguv mugqw
0 ldwjum mugqw sohyp labhvz epqori kfdo
1 xnwpjc agqv lmjoh wvncu tekj lmjoh
0 xnwpjc agqv lmjoh jhnt fhzb xauhq
1 vflcmn pnuvx eolwrj dhfvbt vflcmn toxeyc
0 vflcmn pnuvx eolwrj dhfvbt yetkah bfnxqp
1 rybmae bwcej xnwpjc bwcej yrhefk yhca
0 rybmae bwcej xnwpjc bhck zbfj yhca
1 sohyp htdp symc jrvsyn symc fpoxj
0 sohyp htdp symc eolwrj masq hjzrp
1 dhfvbt yetkah omsaij omsaij dhfvbt tqdef
0 dhfvbt yetkah omsaij zilrh wvncu sohyp
CDSSM overfits on this data. The reason is that it is unknown which word will be useful for matching before actual comparison of sentences. Withal the final matching layer of CDSSM is unable to hold enough information about each concrete word in original sentence. So the only way for network to minimize error is to remember noise in train set. Such behavior is easy to recognize on loss plots. Train loss goes down quickly but validation loss grows - typical overfitting (pic 1.).
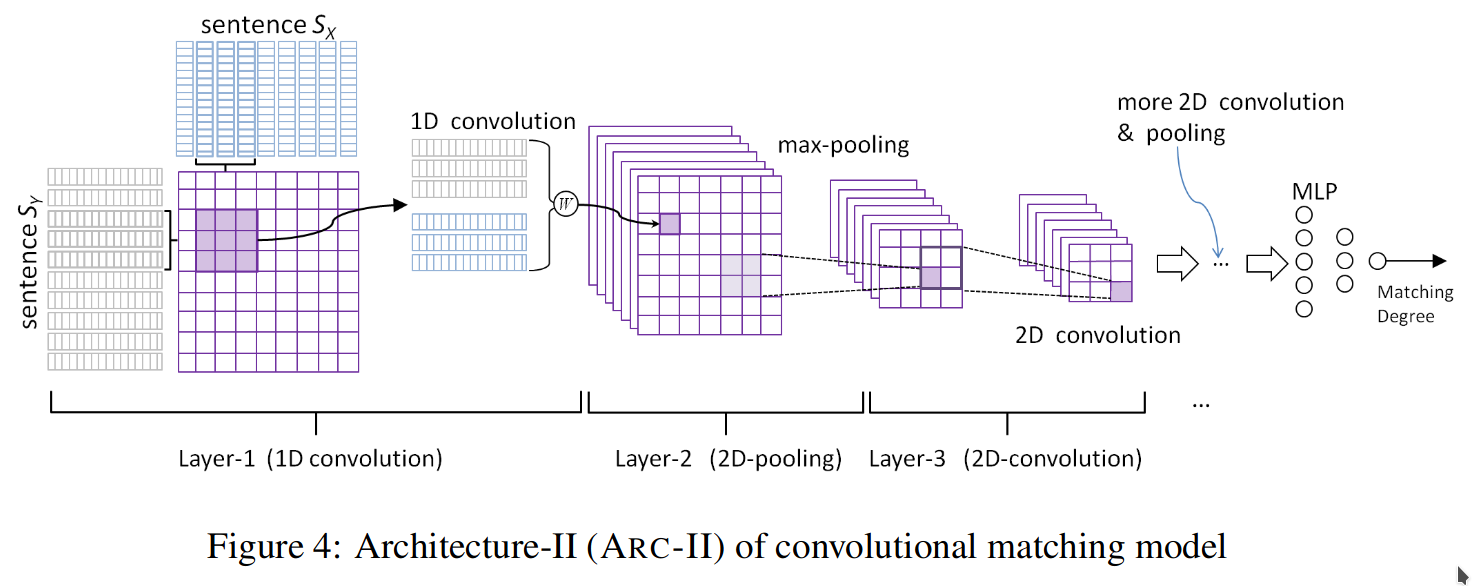
One possible way to solve this dataset is to change network architecture to the one that can handle low level interactions between words in sentence pair. In previous post I mentioned interaction-focused models, the exact type of models we need. I choose ARC-II architecture for my experiment, you can check out implementation here. New model fits synthetic data perfectly well (pic 2.). As a result we can safely skip time consuming experiments with CDSSM model on real dataset.