An important feature of FastText embeddings is the usage of subword information. In addition to the vocabulary FastText also contains word’s ngrams. This additional information is useful for the following: handling Out-Of-Vocabulary words, extracting sense from word’s etymology and dealing with misspellings.
But unfortunately all this advantages are not used in most open source projects. We can easily discover it via GitHub.
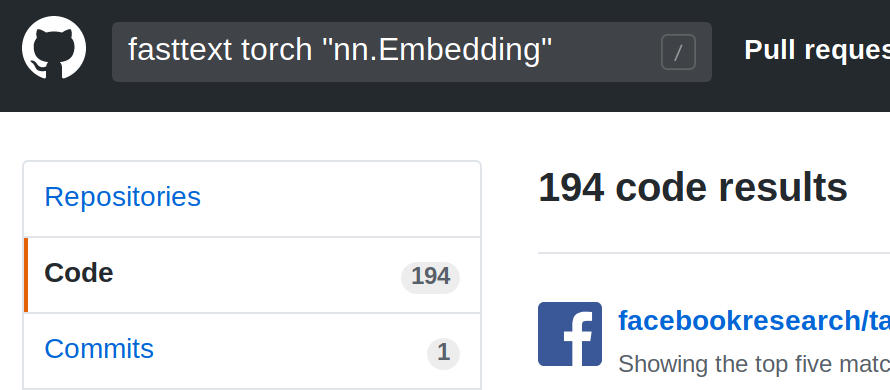
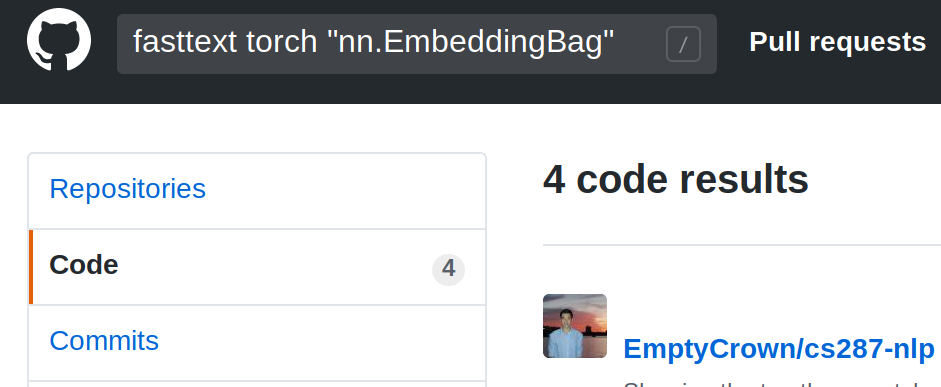
The point is that regular Embedding layer maps the whole word into a single, stored in memory, fixed vector. In this case all the word vectors should be generated in advance, so none of the cool features work.
The good thing is that using FastText correctly is not so difficult! FacebookResearch provides an example of the proper way to use FastText in PyTorch framework.
Instead of Embedding you should choose EmbeddingBag layer. It will combine ngrams into single word vector which can be used as usual.
Now we will obtain all advantages in our neural network.