Let’s continue to dive into Question Answering. Last time we have generated several variants of synthetic sequences, from which we need to extract “answers”. Each sequence type has each own pattern, and we want a neural network to find it. In a most general sense, this task looks like sequence transformation - Seq2seq, similar to NMT. In this post, I will describe how to implement a simple Seq2seq network with AllenNLP framework.
AllenNLP library includes components that standardize and simplify the creation of neural networks for text processing. Its developers conducted a great work decomposing variety of NLP tasks into separate blocks. It allowed to implement a set of universal pipeline components, suitable for reuse. Implemented components could be used directly from code or for creating configs.
I have created a repository for my experiments. It contains a simple config file along with some accessory files. Let’s take a look.
One of the main configuration parameters is a model. The model determines what happens to the data and the network during training and forecasting. The model parameter itself is a class that derives from allennlp.models.model.Model and implements the forward method.
We will use simple_seq2seq model which implements a basic sequence transformation scheme.
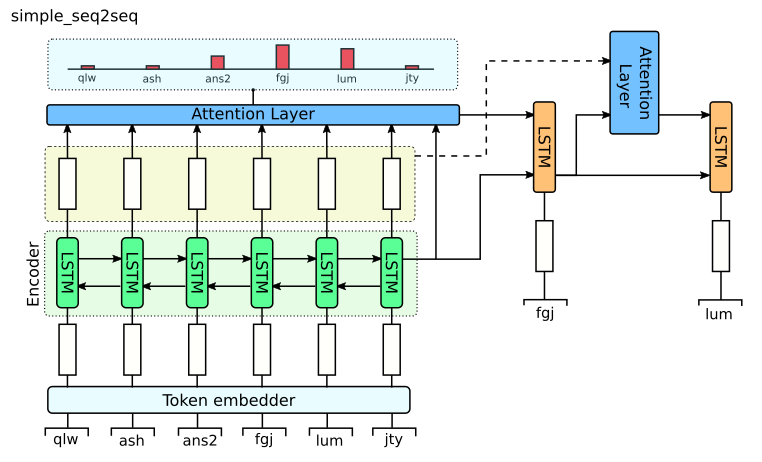
In classical seq2seq the source sequence is transformed by Encoder into representation, which is then read by Decoder to generate the target sequence.
simple_seq2seq module implements only Decoder. The Encoder should be implemented in other class, passed as a model parameter.
We will use the simplest encoder option - LSTM.
Here are some other useful model parameters:
source_embedder- This class assigns a pre-trained vector to each input token. We have no pre-trained vectors for synthetic data so we will use random vectors. We will also make them untrainable to prevent overfitting.attention- attention function, used on each decoding step. Attention vector is concatenated with decoder state.beam_size- the number of variants, generated by beam search during decoding.scheduled_sampling_ratio- defines whether to use real or generated elements as a previous element during decoding.
Then we save our dataset so that the seq2seq dataset reader, implemented in AllenNLP, could work with it. Now we can launch training with a single command allennlp train config.json and observe training statistics on a Tensorboard.
A trained model could be easily used from Python, here is an example.
It should be noticed, that model is quickly overfitting on a synthetic data, so I generated a lot of it.
Unfortunately, AllenNLP seq2seq module is still under construction. It can’t handle all existing variants of seq2seq models. For example, you can’t implement Attention Transformer architecture from the article Attention is all you need. Attention Transformer requires a custom decoder, but it is hardcoded in simple_seq2seq. If you want to contribute AllenNLP seq2seq model, please, take a look at this issue. If you leave your reaction, it will help to focus AllenNLP developers attention on it.